




本文内容大体来自于 哔站视频: 【AI已经涌现出自主意识?从经典论文出发,看懂Ilya到底在担心什么】
剩余多出来的部分是: 自己的主观臆断进行的深层次的解说.
我们会十分尊重原作者的心血和内容版权!!!

向量矩阵(语义矩阵)
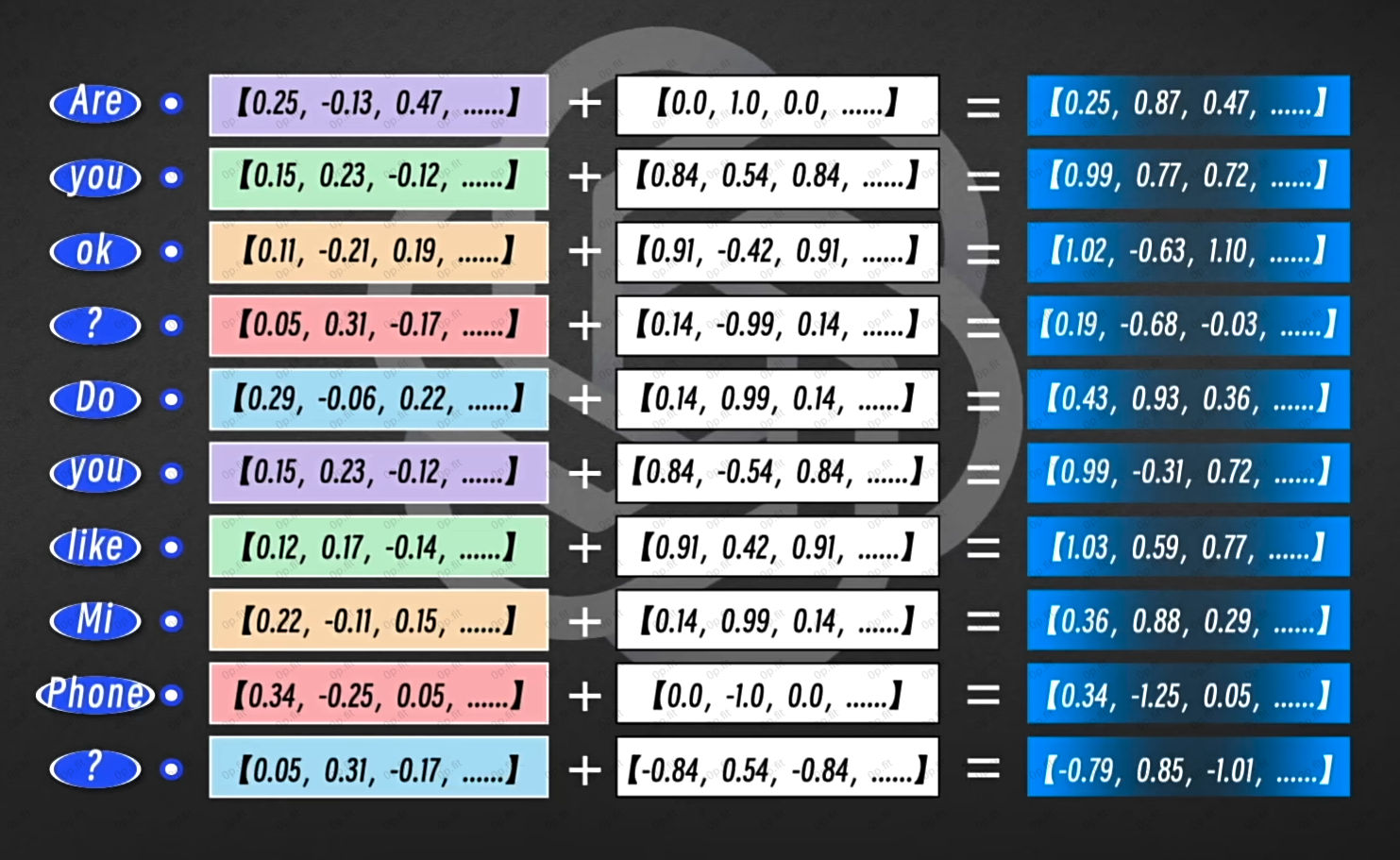
位置编码矩阵(语序)



注意力模块
主要作用: 提取整合信息
就是提取和整合这些纷繁复杂的信息, 然后找到最重要最相关的, 继而对他们分配最大的权重.
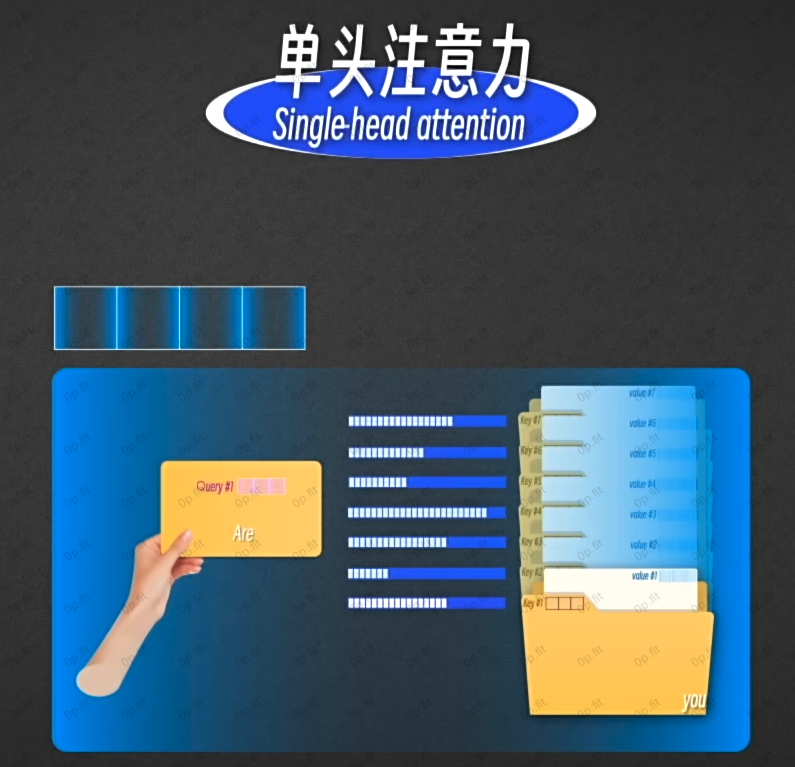
单头注意力
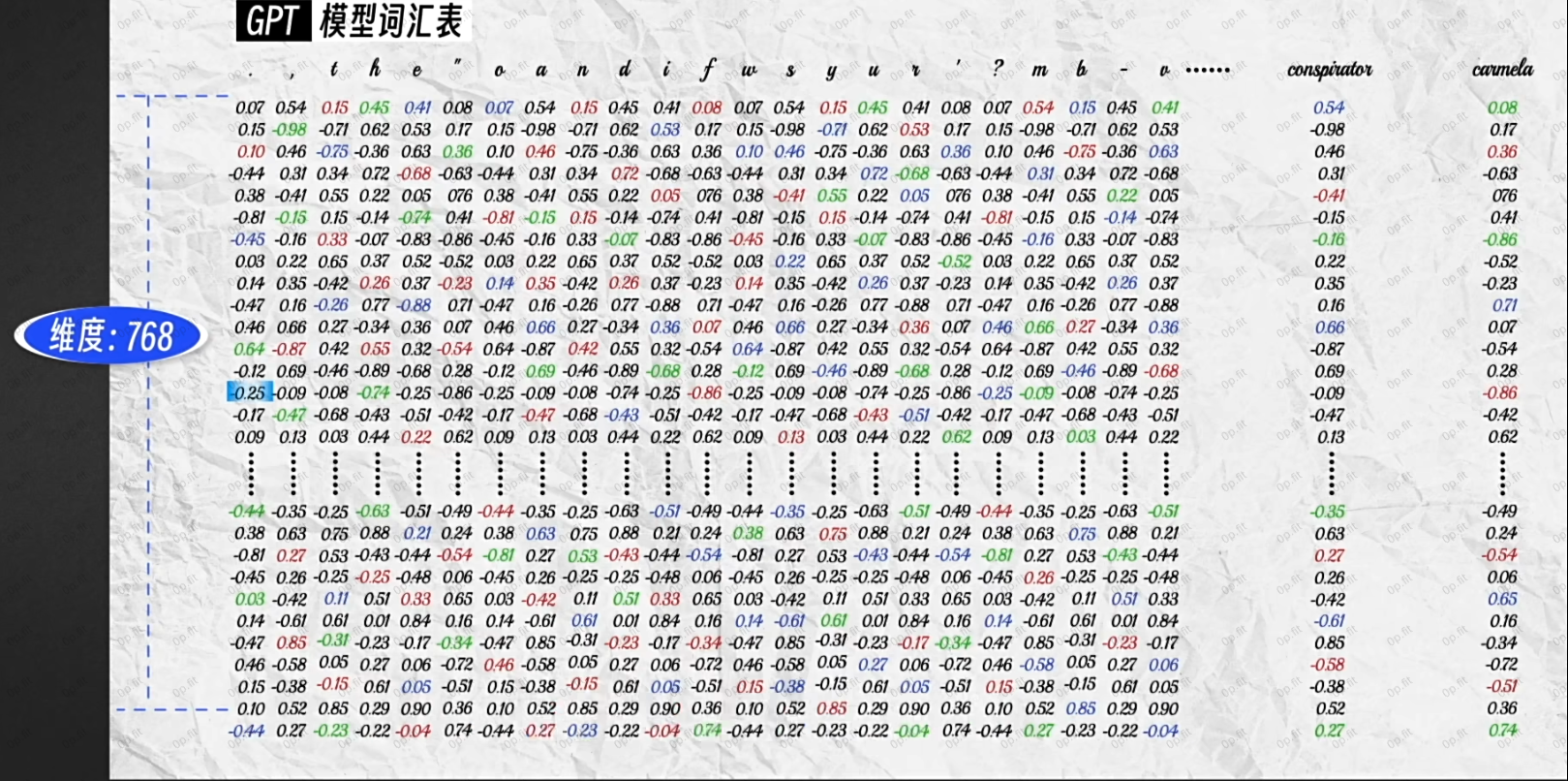
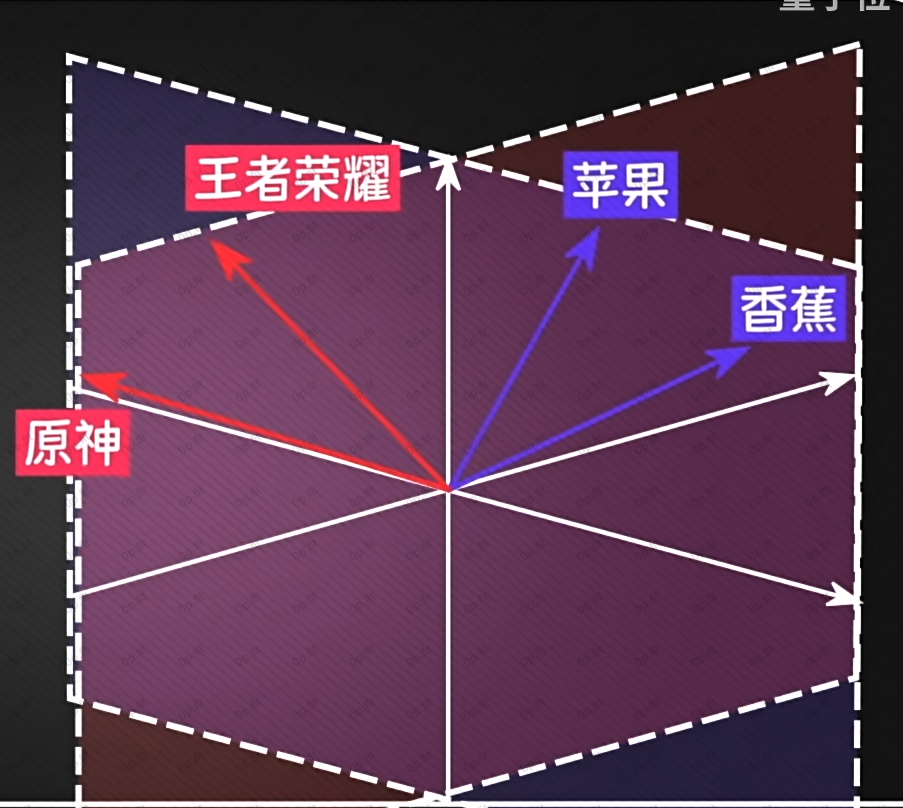
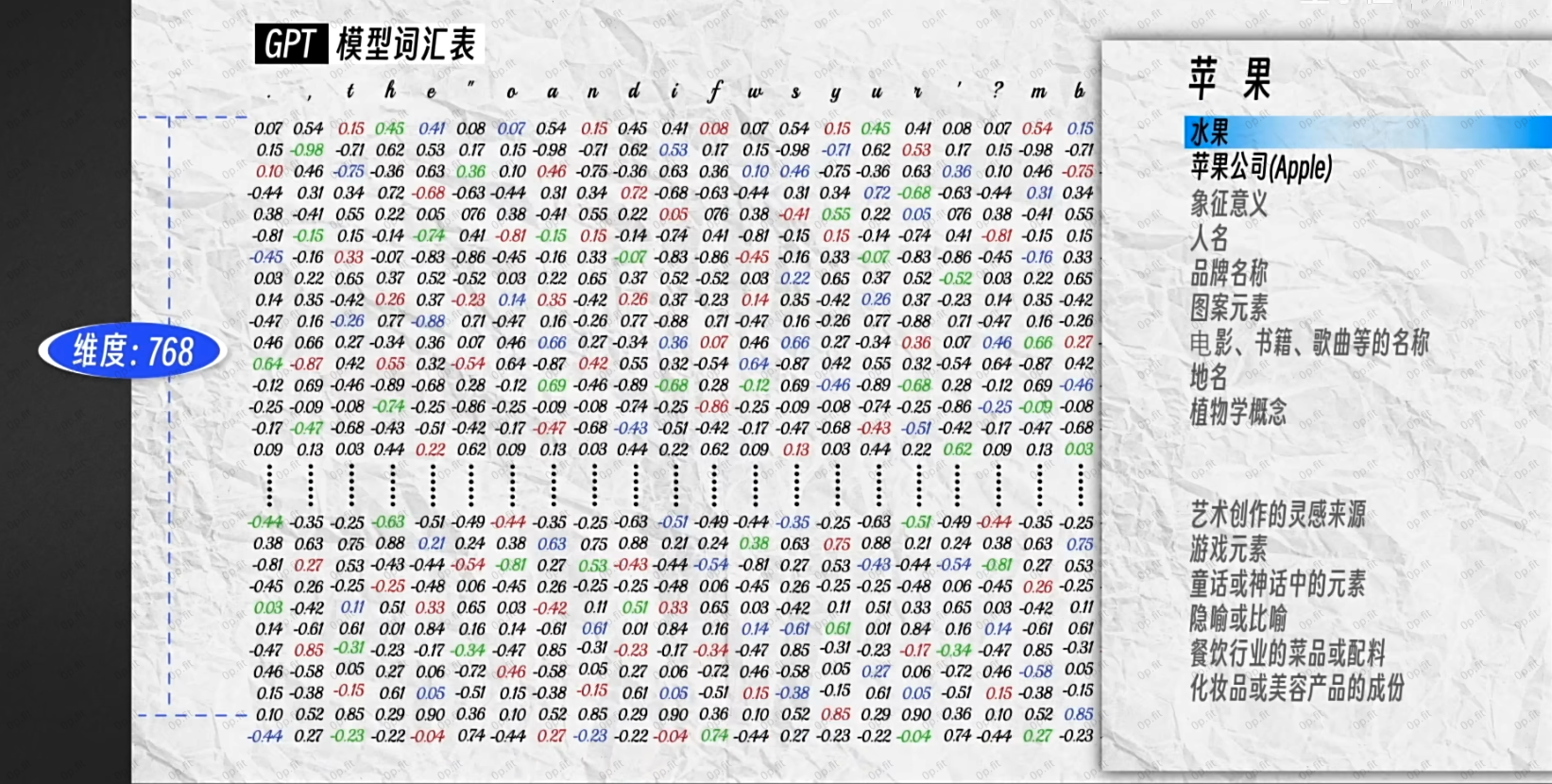
如上图所示, 每个token的输入向量是一列768维的数组, 包含了丰富的语意信息, 但在不同的语境里, 有的维度重要, 有的维度不重要. 比如:

如上图这个语境里, 苹果表示水果的那层语义就没啥用, 就可以不用关注.
权重矩阵

如上图所示, 每个数字大概代表了不同维度之间的关联性和重要性.
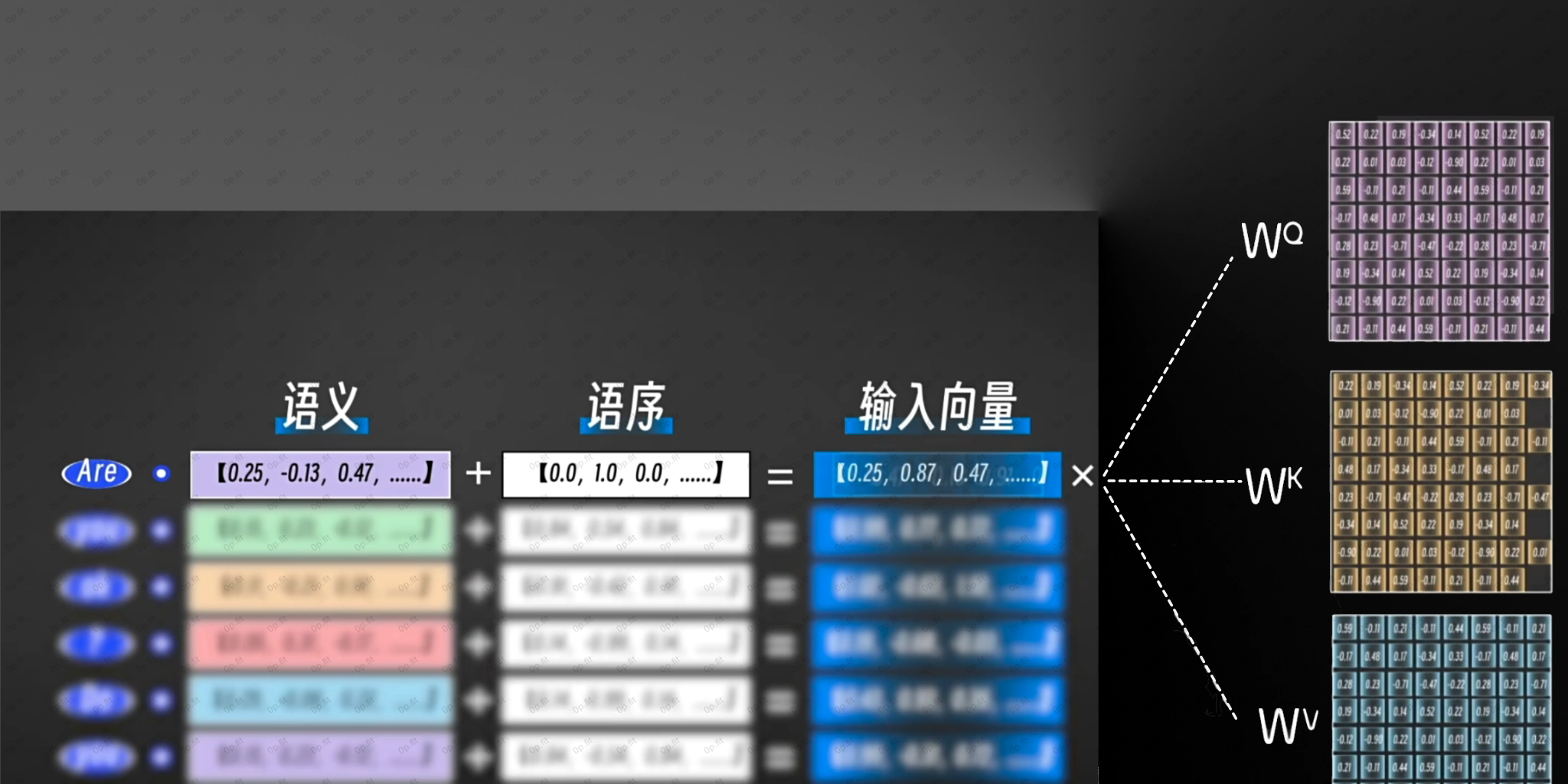
每一个token的输入向量都会分别跟3个权重矩阵相乘, 得到对应的3个新的向量QKV.
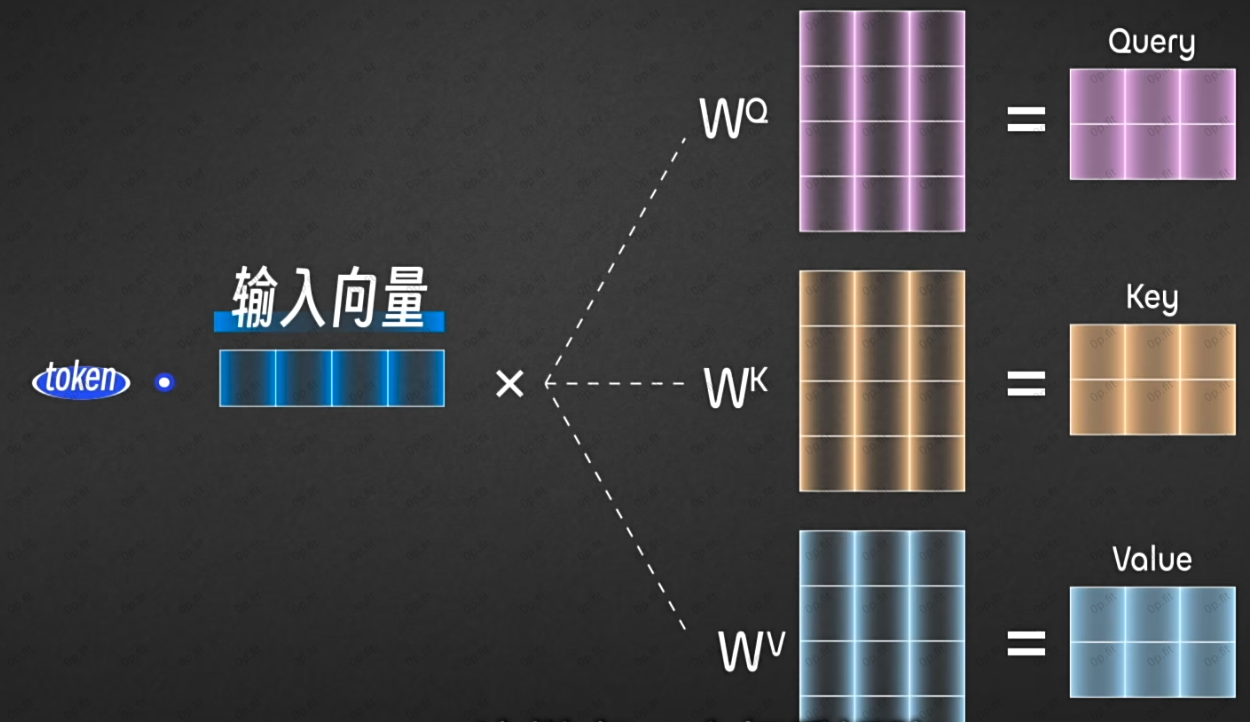
这样的话每一个权重矩阵相当于格子提取了这个token的一部分关联度高, 比较重要的维度.
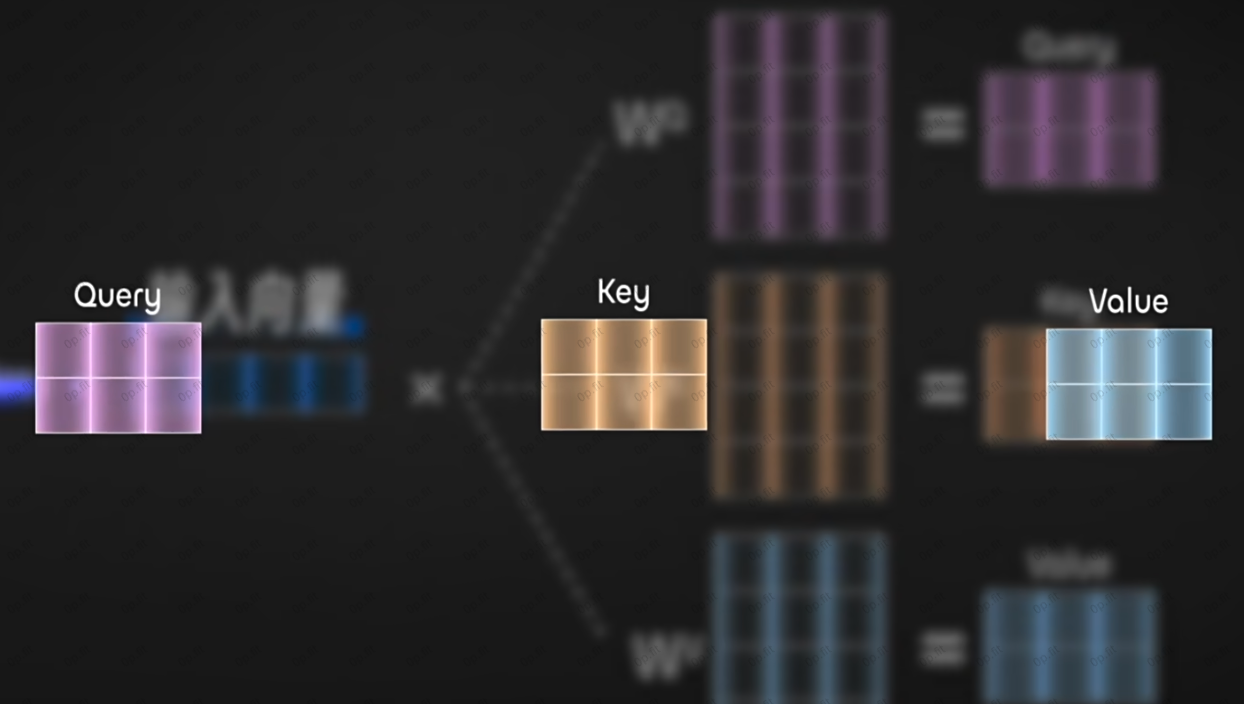
如上图所示, 这三个新向量的作用很好理解. 可以举个例子: 现在, 你需要在一个巨大的文件柜里面找资料.

每一个文件夹代表着一个token, Q向量(Query) 是查找请求, K向量( Key) 是文件夹的标签, V向量是文件夹里的实际内容.
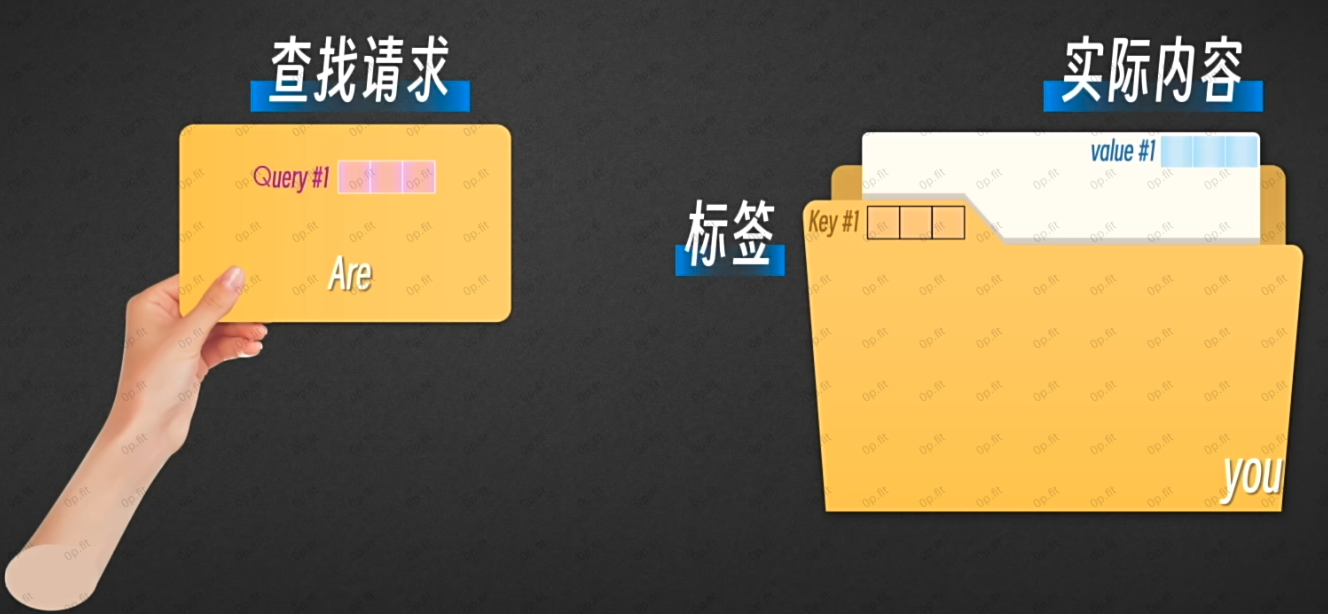
你拿着Q跟文件夹里的所有token的文件夹标签作对比, 计算每一个文件夹的匹配度或者相关性.
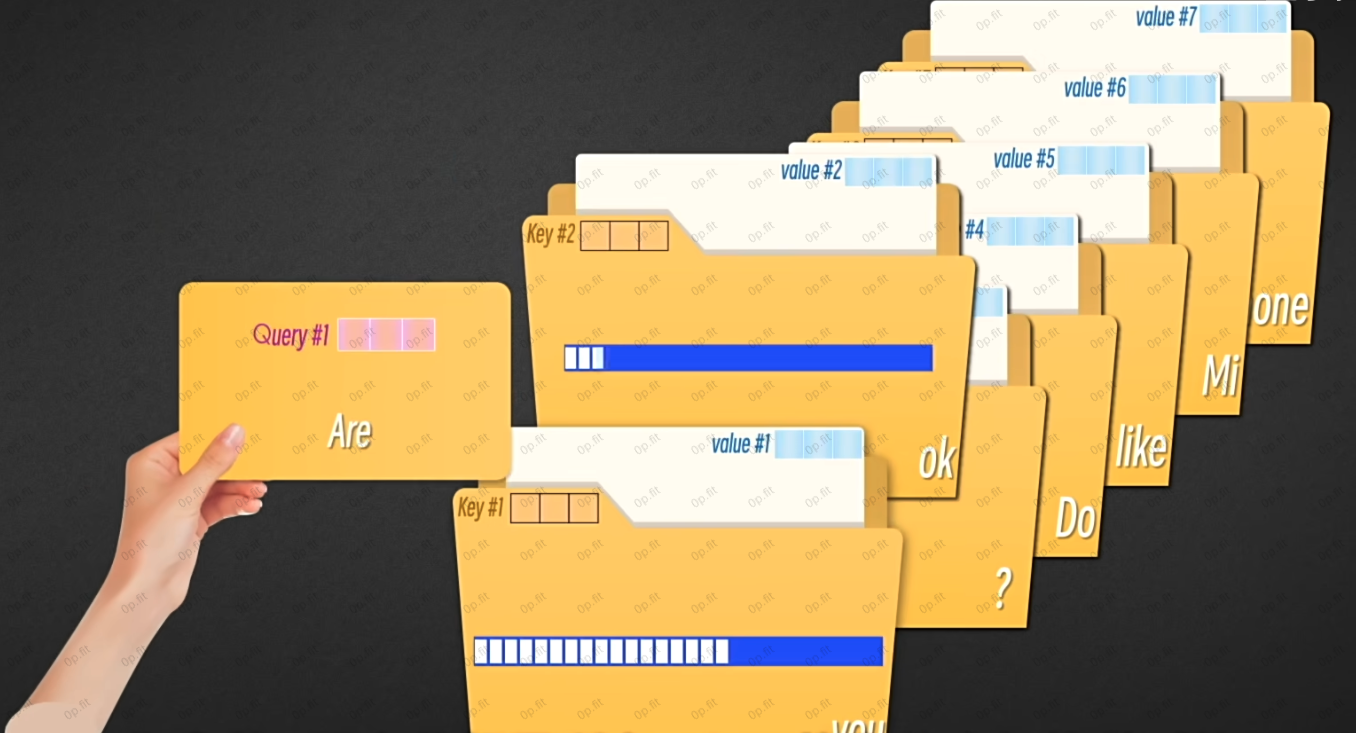 一旦发现了相关性, 注意力模块就会根据相关程度来分配注意力.
一旦发现了相关性, 注意力模块就会根据相关程度来分配注意力.
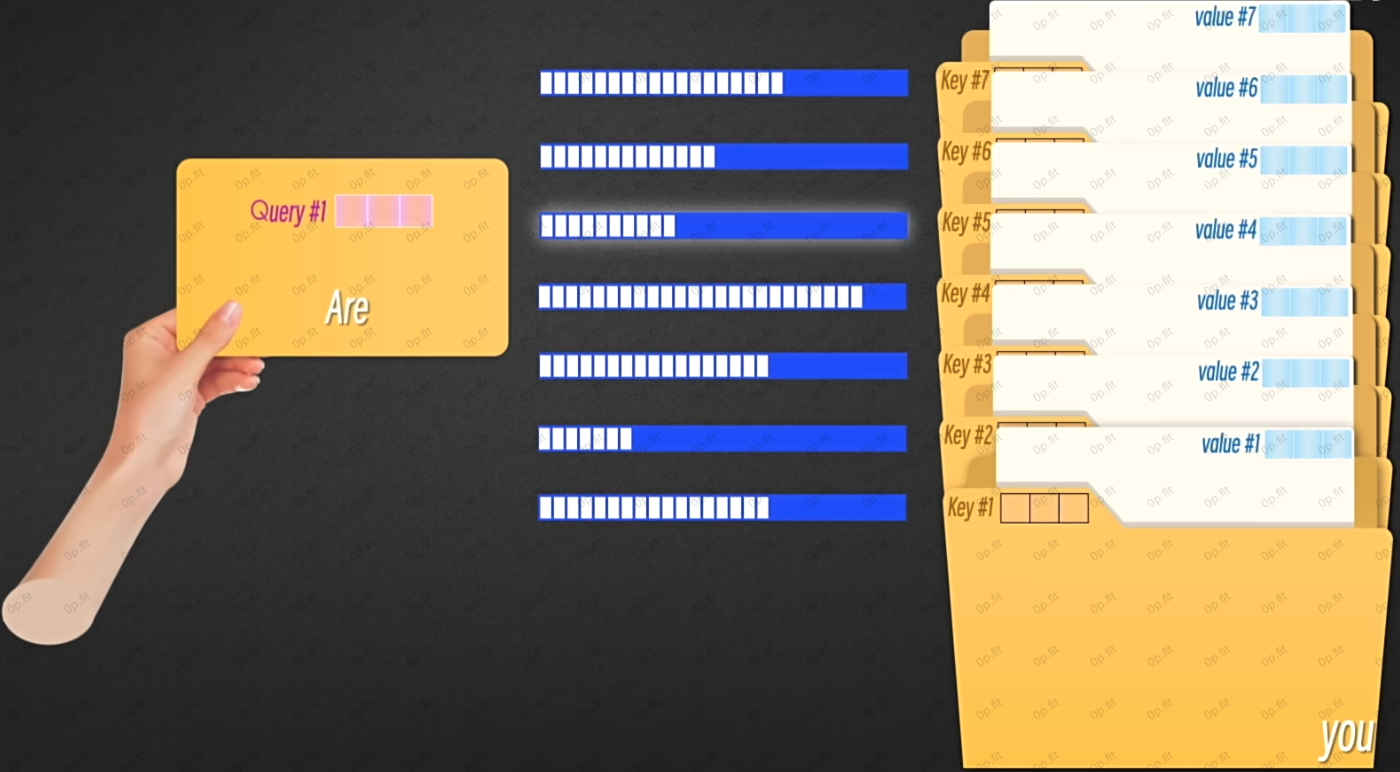

这就是所谓的单头注意力💡.
多头注意力
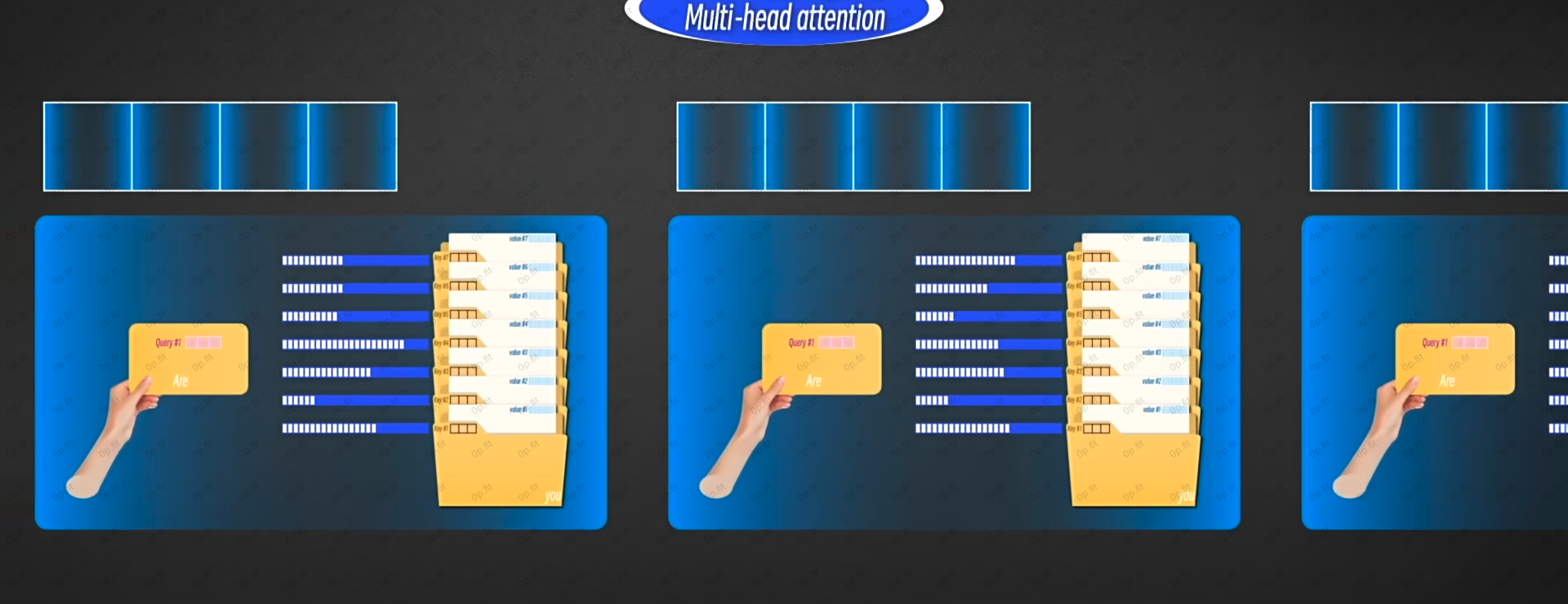
每头注意力关注token的不同的特征, 最后把每个注意力生成的所有新向量拼接起来, 我们就得到了一个包含一定特征和上下文关系的矩阵.

解码
经过第一个解码器, GPT对这句话的理解可能达到了小学生的水平:
GPT-1有12个解码器, 以上的过程会重复12遍, 这意味着GPT对这段token的理解会越来越深入, 直到最后一个解码器吐出最后一个矩阵.

最终矩阵包含所有token的综合特征和上下文信息的精华.




评论区